Yes, we are building clustered solutions to keep as high uptime as possible but sometimes there is a planned or unplanned electrical outage or maintenance work on power lines when we are simply forced to shutdown our cluster – and in that situation we want to do it safely.
When we talk about Storage Spaces Direct (S2D) on Windows Server 2016 / 2019 / 2022 in a hyper-converged scenario (when hyper-v virtualization and storage are inside the same system) it is very important to take care of properly shut down such system not to get in problematic situations where data corruption or some other issues could emerge. Becouse of that Microsoft has a great article about how to safely and properly shutdown a node in S2D configuration.
I would like to share with you a concept that could help you with getting whole cluster safely turned off.
Scenario consists of 2-node S2D solution, standalone hyper-v (on which I run file share witness (for S2D)) and PRTG that by using SNMP monitors APC UPS 2200:
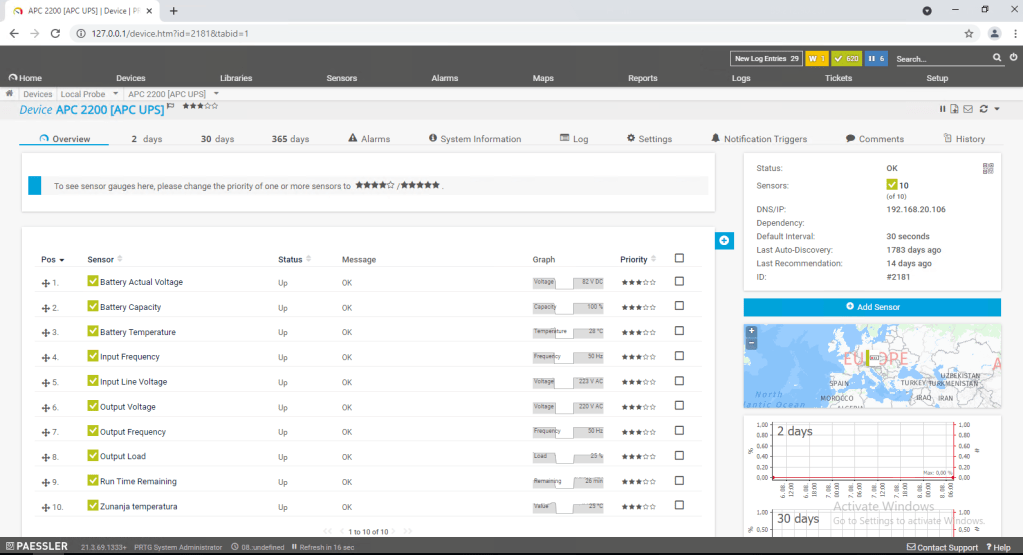
So first of all we need to get the information about Battery capacity by using SNMP query to APC Network management card – this will be the value that we will monitor and based on the current value we will trigger some actions.
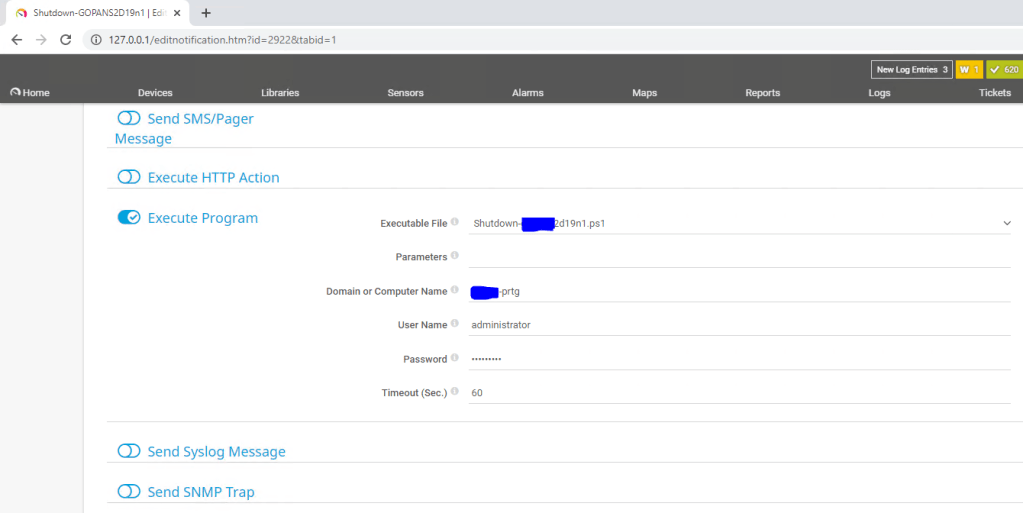
Then we need to prepare Notifications templates where we define Powershell scripts to be executed.
I am using three scripts:
– First script will make a graceful stop of storage services and put S2D Cluster N2 in maintenance mode (all roles will be drained to S2D Cluster N1) after that it will shut down S2D Cluster N2
– Second script will trigger shutdown of all virtual machines on S2D Cluster N1 and after 180 seconds it will shut down the S2D Cluster N1
– Third script will shut down third hyper-v host (standalone)

With the action Execute Program on our Notification Template we define which script we would like template to use and username and password that will be used only to execute the script on local machine (PRTG) – credentials for powershell remoting that will do the shutdown jobs can be safely saved separately so you do not need to enter plain-text credentials to access the hosts anywhere.
After that we need to configure triggers – when scripts will be executed based on the battery capacity – so in my case I decided to set it up like this:
- When battery is on 65% turn off S2D Cluster N2 (drain roles (VMs and cluster service roles to S2D Cluster N1), put the node in maintenance mode, shut down the physical node S2D Cluster N2).
- When battery is on 45% turn off S2D Cluster N1 by firs shutting down all VMs, than wait 180 seconds for shutdown to complete and then shut down physical S2D Cluster N1.
- When battery is on 15% turn off standalone Hyper-V host – where our Witness and PRTG VMs are running
If we check the scriptblocks inside our scripts:
Shutdown-N2.ps1 (the script that in my case we will run first):
In first part of the script we need to setup credentials that will be used to execute powershell remoting:
You can do this buy simply entering username and password into the script (Please do not do that! Powershell allows you to do it way more securely. Please read this article about securely saving encrypted password in separate file.
Invoke-Command -ComputerName S2D-N2 -Credential $credential -ScriptBlock {
$nodename = ‘S2D-N2’
Suspend-ClusterNode -Name S2D-N2 -Drain -Wait
Get-StorageFaultDomain -type StorageScaleUnit | Where-Object {$_.FriendlyName -eq $nodename} | Enable-StorageMaintenanceMode
Stop-ClusterNode -name S2D-N2
Start-Sleep -Seconds 10
Stop-Computer -Force
}
Shutdown-N1ps1 (the second script that will be executed – this will turn off VMs and finaly S2D Cluster N1):
Invoke-Command -ComputerName S2D-N1 -Credential $credential -ScriptBlock {
Get-VM | Stop-VM -Force -AsJob
Start-Sleep -Seconds 180
Stop-Computer -Force
}
Shutdown-HyperV.ps1 (the third script that will turn off stand alone Hyper-V host):
Invoke-Command -ComputerName StandaloneHyperV -Credential $credential -ScriptBlock {
Stop-Computer -Force
}
So the shutdown sequence will be:
– when electricity is turned off and PRTG gets the info by querying UPS that capacity of the battery is under 65 %:
S2D Cluster – N2 will bi gracefully stopped (by draining roles and putting it in maintenance mode and shutdown after that)
– when the battery is under 45 %:
S2D cluster – N1 will be gracefully stopped (by shutting down all VMs and finally shutting down)
– when the battery capacity is under 15 %:
Our standalone host (where PRTG and File Share Witness (needed for S2D Cluster)) will be shutdown.
The procedure to turn the system back on is the following:
– First we will turn on standalone host (and Files Share Witness VM)
– Please do not turn on PRTG server until UPS battery capacity is not over 65% (because PRTG will turn on the procedures again if capacity is below 65%)
– When you checked that standalone host has network connectivity and File Share Witness VM is working and has connectivity too we can proceed further by turning on S2D Cluster N1
– When S2D Cluster N1 is up we can turn on VMs* (as Witness is there and N1 is fully functional you are able to start your production VMs – there will be more data to resync so if you have time it is better to wait for N2 to get back online and put it out of maintenance mode.)
– We can now turn on S2D Cluster N2 and when it comes back online we need to bring it back into fully functional Cluster member state by executing the script:
$ClusterNodeName = ‘S2D-N2’
Start-ClusterNode -name $ClusterNodeName
Get-StorageFaultDomain -type StorageScaleUnit | Where-Object {$_.FriendlyName -eq $ClusterNodeName} | Disable-StorageMaintenanceMode
Resume-ClusterNode -Name $ClusterNodeName -Failback Immediate
After executing the script you can check the progress of storage re-synchronization by executing Powershell cmdlet: Get-StorageJob
When UPS battery capacity reaches over 65% you can turn on your PRTG monitoring system again.

Good article. Will this differ any if I have a 3-nodem, instead of 2 nodes, S2D cluster? What if I do NOT have a quorum witness in use? Also, don’t you have to run the below command on each node:
Get-StorageFaultDomain -type StorageScaleUnit | Where-Object {$_.FriendlyName -eq $ClusterNodeName} | Disable-StorageMaintenanceMode
You only indicate you are running it on Node 2! Should you run this same command on Node 1 as well?
Thanks in advance, Scott
LikeLike
Scott. I would do the same with 3-node system by using the same script on node 2 and 3 – in two node scenario witness is important to get the idea where the majority is and start CSV …
I am running the script that puts storage in maintenance on node2 because node1 at that time is still active (with active VMs (and so – making changes)) but when I shutdown VMs on node1 (that will be later the first node, that we start after power is back!) I do not think it would make any difference to enable maintenance on node1.
LikeLike
Thanks for the quick feedback! Much appreciated. For whatever reason, I can not find much documentation on the internet about having a full S2D cluster outage.
So back to my thought process, when I take the 1st of 3 nodes out of the rotation, I run the below two commands directly on the host:
* Suspend-ClusterNode -Drain
* Get-StorageScaleUnit -FriendlyName “HV-CAM01” | Enable-StorageMaintenanceMode
I have NOT been running the below command that you have in your shutdown script:
* Stop-ClusterNode -name S2D-N2
Should I be running the Stop-Clusternode command on each host and the corresponding Resume command when the nodes come back online? Just trying to determine what the difference would be, and what the thought process is there. It seems to be working fine in the past without me running the Stop-ClusterNode command.
Another thought, so you are indicating when I bring down the last of my 3 nodes, I do NOT have to place the storage in maintenance mode? Are you further indicating that I would NOT have to run the Suspend-ClusterNode command or the Stop-ClusterNode? Thoughts….
Lastly, I was actually thinking about shutting down all my VMs but one prior to even taking the 1st node down for maintenance in hopes that I would reduce the time for the storage to sync back up. Typically, the storage takes anywhere between 8 to 15 hours to sync up historically regardless if a node has been out of the rotation for 15 minutes or 2 hours…
Does it matter which node I bring back up 1st once my maintenance is done?
Much appreciate all your time and energy on your feedback…
Thanks in advance…
Scott (Tampa, FL)
LikeLike
Hi!
Should I be running the Stop-Clusternode…. I think this will give you more control when you are bringing the whole system back online. So you will have a clear idea what is going on – OS is booted you are logged in and then your resume… Just to have more control not to overlook something that might happen before you are logged in.
Lastly, I was actually thinking about shutting down … Yes, I think you are doing it right! In my case (two node scenario) rebuild is usually quicker and also it can happen that electricity comes back while first node is still active (with running VMs) … In such case I would only bring node 2 back online and resume it (resync would kick in…). But yes if you decide to bring everything down than first thing would be shut down the machine and in such way reduce the potential resyc time…
Does it matter which node… Well in my case it matters as node 1 has more “fresh” state (as VMs were still running on it while node 2 went down…) and I do not want some funny stuff to happen. And another thing. I made a strict step by step paper for my colleagues to go strictly through procedure for shutdown and turn on…. I do not want to confuse potential colleague with the possibilities 🙂
Big hello to Florida! 🙂
LikeLike
Thanks Luka! So that makes sense about starting the node that has the most “freshness”. I like that technical term…lol
I have never done a full S2D cluster outage on this system before. So I am trying to create a precise checklist. I don’t want to script it out. I am not sure if you answered my question thoroughly about the last node that I bring down. Should I run all 3 commands (drain node, Maint, Stop-Clusternode) or just the maintenance command?
Again, your time and energy is much appreciated…
Scott
LikeLike
On node 3 and 2 I would do maintenance and then stop. When you will do it there node 1 will probably put it in pause anyways… By the way – if you would like to test this scenarios I can give you access to virtualized environment where you can try it out… Just drop me an e-mail…
LikeLike
Sure, would love to utilize a virtualized environment. Where are you located?
LikeLike
Scott, in Slovenia – Europe. Send me an e-mail to luka AT manojlovic.net
LikeLike
Hey Luka, what it benefit me to take a Checkpoint of the VMs I have before I start this maintenance on the S2D cluster? I plan on doing a file level backup before I start the maintenance…
LikeLike
Why checkpoint then? Why don’t you just copy whole CSV content somewhere else? Maybe I do not understand completely what you would like to achieve. But another thought … Stay away from checkpoints … 🙂
LikeLike
Hey Luka, I have my S2D full-outage maintenance window tomorrow.
I actually found another article that actually briefly talks about how to do the full S2D maintenance outage. Link below:
https://jtpedersen.com/2019/01/so-you-have-not-patched-your-storage-spaces-direct-cluster-in-a-year/
With that said, the essence of that article is illustrated below:
**********************************************************************
Offline
Here you stop all cluster resources, stop the cluster and disable the cluster service on each node.
Pros
Fast, very fast actually from start to finish
No risk of data loss
No rebuilds as cluster is offline
**********************************************************************
From what I gathered from this article, instead of placing each Host into maintenance mode 1 at a time, I simply run a PS command to Stop-Cluster, Stop-ClusterNode, & finally disable Cluster service on each node until all my required reboots are complete??? So rebooting without placing the storage in maintenance mode…!!! Just doesn’t sound right..
In the last line as a Pro over the Online process, this article indicates “No rebuilds as cluster is offline”… I just don’t know if I can take that at face value…
Your thoughts?
My current process of placing 2 0f the 3 Host into maintenance mode, and trying to figure out if I truly need to place the last node standing into maintenance mode or NOT prior to rebooting the last node standing…
Just so frustrating that I can NOT find a soups-to-nuts full S2D cluster outage KB article with details ANYWHERE on the internet, and even on MS web site…
Any Thoughts are suggested…
Scott Caryer
LikeLike